As said above: In spite of an immense lot of research
and new knowledge during last decades there is no consensus on
how to interpret the genetic code and the system for protein synthesis
but a lot of quite different hypothetical aspects and approaches.
To really get the faintest idea or intuitive guess on the development
of a cell - and life, it's proposed here as necessary to start
from general assumptions as the following ones, some of them surely
shared by many, others more controversial.
a. The enormous complexity of the cell and its metabolism must
be understood as an internal differentiation, through opposite
forces, which implies starting from some kind of (partly) enclosed
"unit", defined by a centre and an substantiated "anti-center"
as a partly penetrable circumference. (This could perhaps in a
first stage be some kind of metal shell - analogous to later Me-skeletons
of unicellular organisms; metals representing anticenter in relation
to non-metals, the main structure-building elements of life.)
b. Next, about forces, it must be assumed that all forces
recognized at the level of physics (probably redefined in the
future) appear on
the biochemical level too, in one or another form, not
just the electromagnetic one. (Naturally also aspects from quantum
mechanics.)
c. Further, about dimensional conceptions on the biochemical
level: To get the slightest intuitive comprehension of the biochemical
complexity, it seems quite necessary to extend the dimensional
analysis to higher dimension degrees (d-degrees). It would imply
that aspects on structure in simple 3D-terms were integrated with
other biochemical gradients of different kinds - binding and polarizing
ones - as 4-dimensional vector fields, into some unified, multidimensional
analysis.
It's surely also time to leave the concept of
dimensions defined only in terms of "independent" variables
(already questioned in physics) and adopt a view where dimensions
are deeply integrated and interdependant in dynamical processes.
d. The character of the genetic code as an information system
should be closer analysed: Is it a reference system between connected
complementary forms, a memory system and / or a parallel
development of the same structural kind on different levels, where
underlying level becomes the "memory" ... or is seen
as "representing" the superposed one - or the inverse.
Perhaps it's only part in a more general system of references
connected with concepts as inversions, resonances, conjugates,
complementary units - and relations between different, dependent
d-degrees?
e. Then, about mass, mostly disregarded when the genetic
code is discussed. Mass is a property not yet understood by physicists.
That shouldn't be taken as a reason for regarding mass as an unimportant
property for the emergence of life. Sooner, it would be extremely
astonishing if not all atomic properties played essential roles
at the creation.
The main objection to reevaluate
mass is surely such experiences which seem to show that some unusual
isotopes don't change the studied metabolism in an established
cell milieu of today.
Smaller changes of isotopes may be possible
to neglect in properties as structures and volumes of molecules,
(even if they theoretically should influence gradients in mass
fields, if this term is allowed),
However, does such facts necessarily contradict
a presumption that mass of common isotopes had a decisive importance
at first configurations of elementary biomolecules?
It is reasonable to assume that mass is a property
of higher d-degree, representing a deeper level, than charge.
(The physicists' application of the gravity concept into microcosm
and quantum mechanics could be mentioned here.) If so, it would
agree with dimensional views that the deeper mass level was decisive
for elementary structures, while the more superficial level of
charge, expressed in electron shells, becomes the relevant level
in processes, in metabolism as characterized by more of released
kinetic energy.
Further, in research to find shortened ways
to predict destinations and functions of proteins, mass is used
as one factor besides polarity with obviously good results [1].
About counting on ordinary isotopes, the overwhelmingly
most common ones, it could also be reason for reminding of the
carbon-nitrogen cycle in the sun, where it is the 3 alpha carbon
and 4 alpha oxygen that make up the start and end of the fusion:
4 protons (H) giving an alpha-particles (4He).
Some more about this matter in concluding remarks.
f. Looking for an eventual guiding principle behind emergence
of the code, where could it be found? If it isn't regarded as
an invention from heaven, it's unavoidable to look for the guiding
principle somewhere else, most naturally expressed in the singular
atoms themselves.
Hence, we could suspect that the atoms themselves
- with their underlying relations in the fusion processes - should
serve as microcodes for cellular life and the principles guiding
it. Those principles should probably be found in their internal
configurations, also deeper in their nuclei and on a higher level
in their spectral lines?
g. Finally, about numbers in general, it's hard to see
why numeral series as such should be regarded as special exceptions
when appearing in Nature. Different elements are regarded as characterized
by numbers of units (u) and on a molecular level by protons equivalent
with electrons and their relation to the "octet rule".
Since all matter - as well as radiation - is quantified, it shouldn't
be too strange to find underlying arithmetical relations behind
the structuring principles in the genetic code.
Most scientists in the field may perhaps feel
inconvenient with this idea, regarding it too abstract for any
practical work. However, since pure mathematics has led to deeper
understanding of nature on the level of physics and astronomy,
why shouldn't it in biochemistry?
In fact, such number series could be compared
with structure drawings for buildings, revealing mutual relations
between later, stepwise materialized structures. Or perhaps more
resemble the principal scheme for the working processes, the logistics?
Just the way of Nature to organize itself.
After all, the numeral series behind the periodic
system didn't "exist" - in any recognizable form - in
the first materialized Universe after Big Bang.
Rather few contributions to interpretation of the genetic code
have paid attention to number regularities as it seems (among
references chiefly [2 and 3] but also in one aspect [4]). Recently,
according to reference [5], it has been shown that the human genome
as a whole single strand is of a fractal kind regarding frequency
of codons.
Since long ago it's observed that features of
Fibonacci number series and the golden section appear in Nature.
(Below it's shown that such series show up also in mass analysis
of the genetic code.)
There are more general and recognized numeral
series: One very simple example is the valences of the central
structuring elements in the genetic code: P - C - N - O - H with
valences 5 - 4 - 3 - 2 - 1. (A suggestion here is that numbers
also could refer to d-degrees or to dimensional steps, presumably
as fractals, with the same patterns reappearing on different levels
of evolution.)
Another essential example is the 2x2-series
(x = 5 - 0), 50 - 32- 18 - 8 - 2, behind the periodic
system, with intervals
defining number of electrons in the different orbitals, the orbitals
p, d, f also occupying increasing d-degrees in their orientation.
It's natural to assume that the arrangement of electron shells
have correspondences in the atomic nuclei, responsible for most
of the atomic mass.
A third example is the formulas for spectral
lines of hydrogen, where differences between inverted squares
of integers as n = 1, 2, 3, 4 and m = 2,3,4, 3,4,5 etc. times
a constant give the wavelengths.
Quotients between wavelengths (n = 2, m = 5,
4, 3) in the Balmer series times 102 happen to give
the mass numbers of U- and A-bases too (112 and 135) and approximately
the G-base (151,2), which could awake some suspicions...* (Quotients
as a kind of phase waves? Alleged not to carry any information!)
Fig 1-1: From Balmer series for spectral lines of hydrogen:
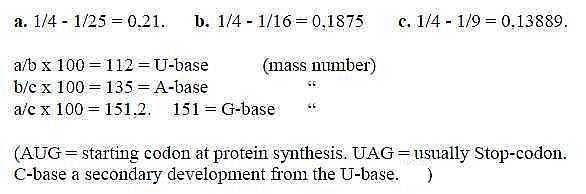
(C-base eventually later developed to give two pairs?
Last term in c. = 1/9, x 1000,
= 111,1. C-base = 111 )
To Table
of amino acids and first observations.