The amount of correlations between the genetic code and numeral
series is difficult to regard as only random ones.
A general problem is of course that it still doesn't
seem to exist any known biochemically accepted mechanisms that could
"explain" construction along such numeral series, however
established facts in the other mentioned examples. It could however
be questioned in which sense the 2x2-series behind the periodic
system is "explained", or the formula for spectral lines
of hydrogen.) Facts are there. Science has only its models, as far
as possible congruent with the facts.
With the hypothesis here that they really reveal features in how
Nature organized the genetic code, what should it imply? About the
elementary series 5 →> 0,
the series of valences for atoms in the genetic code could be remembered:
P - C - N - O,S - H = valences 5 - 4 - 3 - 2 - 1. A dimensional
interpretation seems inevitable, with regard to exponents and to
transformations between nb-systems.
How should the exponent 2/3 be explained? We have squares in the
2x2-chain behind the periodic system and intervals between
inverted squares behind the spectral lines of hydrogen. These formulas
concern electron shells of atoms, i. e. the property charge. With
mass and charge most elementary assumed as a mutual relation D3
to D2, cubes become natural. We have mass as the energy form concentrated
in atomic nuclei, charge expressed in the atomic shell with released
energy in kinetic form. Why then inverted cubes? They lead inwards
to a deeper level, as does the inward direction toward nucleus in
an atom.
One association goes to such celestial bodies as white dwarfs, where mass is inversely proportional to the cube of the radius. (Another may be the general feature of atoms in a full shell of the periodic system, in which the radius decreases towards heavier nuclei.)
The many relations of disparate kinds to the 2x2-chain
and other simpler chains support the interpretation of the genetic
code as built on an elementary chain x = 5 - 0 with exponents of
different degrees. With a dimensional view on the exponents, it
could imply, either that such chains preceded the more elaborated
ES-chain when the coding system emerged or could be regarded as
simultaneously existing on underlying levels. It's possible to imagine
a dimensional development from both ends of the chain towards step
3 - 2 in the middle with increasing agreement of mass distribution
in the genetic code:
x4 → x3
→[ x3/2
→← x2/3]← x2←
x1.
The mass distribution as described in section I often implied minus/plus
lower numbers in the ES-series, correlating with features in the
background model. It points to a two-way direction in he chain of
both disintegration and synthesis. This could seem to conflict with
the common view on evolution as a stepwise synthesis towards more
complex and bigger units. Yet, a double-direction is natural in
Nature, if we think of macrocosm, Big Bang and both processes in
celestial Hx-clouds. It could be mentioned that even among physicists
this opposite view of disintegration, starting from a whole, has
been proposed. (There is a similar pattern of two-way direction
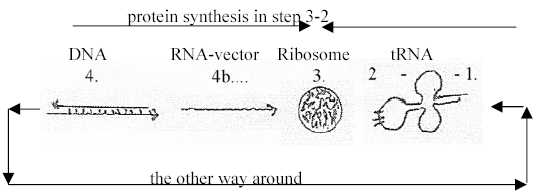
in the protein synthesis, where tRNAs as from opposite strands of
DNA meet mRNA "the other way around" at ribosomes in the
"middle" of the process.) See figure
here, with dimensional interpretation of the forms from
double direction (D4) in DNA to single-strnded RNA as vector (pole
4b) outwards to ribosomes (D3) - meeting tRNAs (as "clover
leaves" D2) and ams.
It's shown too that not only mass distribution on codon groups
of ams correlates with the ES-chain but also other bases for
mass division, for instance with main groups of atom kinds and the
not codon-dependant B-chains as well as with several features in
the origin of ams from stations in glycolysis - citrate cycle. This
suggests an interpretation where the same principle scheme is developed
on different levels or as representing different axes in a coordinate
system when the genetic code emerged.
The single fact that the mass division on C-skeleton
and other atoms (960 and 544) is the same as between main codon
groups (U+A, 960 and G+C, 544) supports in itself the general suggestion
that the code is built on a numeral series.
In several ways the results seems to agree with the coevolution
theory [6, 7]. There is the relation with biochemical origins of
ams from glycolysis and citrate cycle. There is the view of codon
domains as totals, differentiated in following steps, even if the
"codon domains" here is related to mass sums of ams. There
is also the fact that G1-coded ams "arrive first" in the
number chain as 5 out of about 7 ams assumed first in that theory:
GG-GC-GU-GA-GA besides Ser UC and Phe UU..
Then about mass again, rejected as irrelevant for codon assignments:
In addition to arguments in the Introduction it's reasonable
to ask for instance why precisely these ams have been selected for
coding, not other ones? The selection seems rather random. Why just
this number of ams with oxygen as end groups, that number of ams
with nitrogen? (Besides that both types and polar and non-polar
ams surely have been necessary.)
Further, when much research in this field has
been focusing on the "most stable" configuration of the
coding system, one could naturally ask what the background is for
this stability? One aspect is of course that the most common isotopes
have shown up to be most stable. (When calculating with common mix
of isotopes today, atomic weights should change the sum of R- plus
B-chains of ams from 3276 →>
3280 abbreviated, R-chains from 1504 →>
1506, no more than the deviations of single units (u) in this analysis.)
In addition, the analysis here mostly concerns groups of ams, i.
e. sums were an individual deviation in mass might have a rather
small influence.
The fact that Ileu sometimes gets mixed with Leu
by tRNAs could also be mentioned, differing in structure but having
the same mass and atoms.
Does the proposal for a guiding numeral series exclude such an
individual invention among certain organisms as Pyl, called the
22nd ams, occupying a stop codon? Pyl adds 108 to R-chain of Lys,
i. e. the interval 3' to 1' in the ES-chain and could eventually
be suspected as a "misreading" of the chain, leading to
a compound, a new "word"?
The examples of transformations between nb-systems are astonishing
and certainly provocative. They support however a general dimensional
view in the creation of the code and actually too the relevance
of the ES-chain. They seem to reveal a deep level in the reference
system of a hitherto unknown kind, representing the very steps between
dimensional degrees. In physical and biochemical terms they should
imply something like mutual resonances between "mass fields"
in different dimensional degrees, relations and fragmentation guided
by geometrical and arithmetical rules. A problem is naturally the
superfluity of such possible transformational relations.
If proposals in this paper are accepted as hypotheses, they will
naturally raise many new questions and lead to secondary hypotheses,
which in their turn could be possible to test. The dimensional aspects,
mostly omitted here, should reasonably, if elaborated further, have
implications for protein structures and their different functions
in cells.
Whatever to believe about the arithmetic, something
of that kind resembles life
- in being very simple and very productive - and naturally multidimensional.
*
{kind=link}